Transaction 在中文裡常被翻譯成「交易」或「事務」,但其實它跟買賣交易完全無關。Transaction 代表的是將一段 SQL 指令丟進資料庫系統執行,並確保這些操作的完整性。那麼,Transaction 在資料庫系統中是如何運作的?需要符合哪些規則?讓我們一步步來了解。
💡 小提示:Transaction 常簡寫為 TX 或 Tx
在馮紐曼架構的電腦中,每個指令(這裡指的是機器碼 machine code)都會經歷三個階段:
資料庫的 CRUD 操作同樣逃不了這個循環。
在早期的循序操作 (Serialized) 模式下,同一時間只能執行一個指令。當某個指令讓 I/O 或 CPU 閒置 (idle) 時,其他指令無法使用這些資源,造成嚴重浪費,效率極差。
用個比喻來說,就像是「占著茅坑不拉屎」——資源被占用卻沒有充分利用。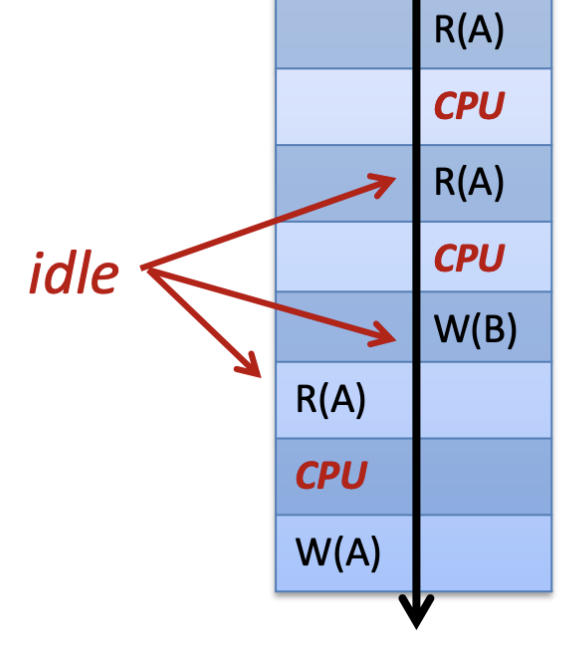
為了解決資源浪費的問題,資料庫系統引入了並發執行 (Concurrent Execution) 機制,讓同一時間可以執行多個 Transaction。當 Transaction A 處於 idle 狀態時,可以把資源讓給其他需要的 Transaction。這種交錯操作 (interleaved) 可以大幅提升 throughput(吞吐量)。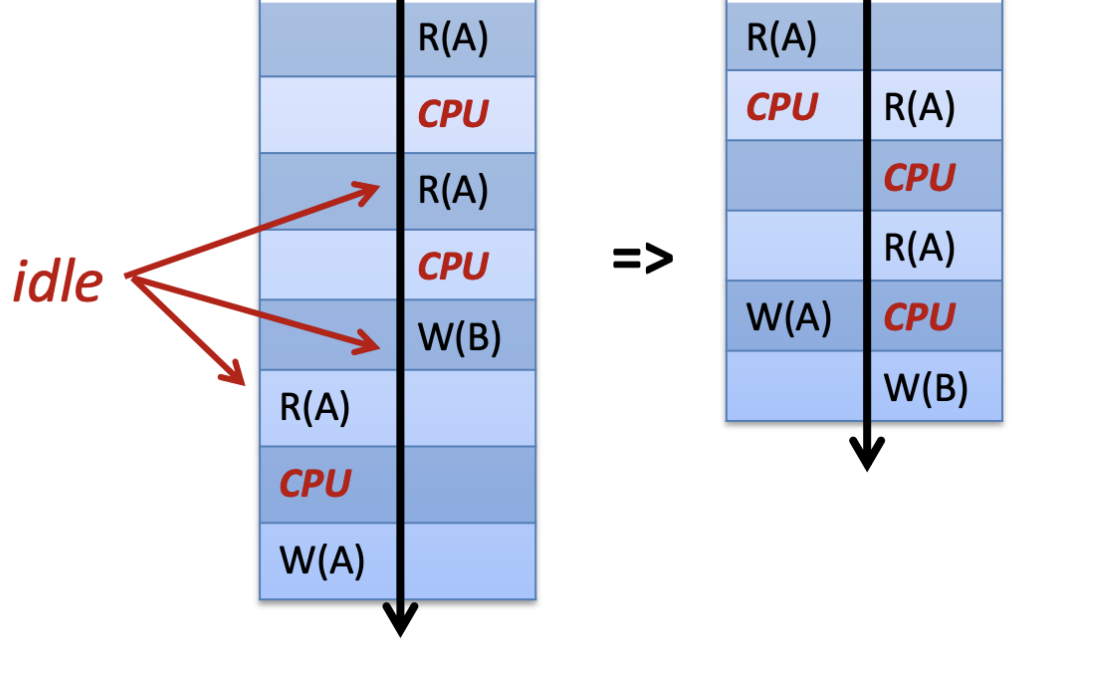
但是,並發執行也帶來了新的問題——並發性 (Concurrency) 問題。
當多個指令同時操作同一筆資料時,可能會發生資料覆蓋、讀取到不一致的資料等問題。
我們的目標是:在交錯操作的設計下,讓每個操作的結果都如同循序操作一樣正確。
最直觀的解決方法就是加上鎖 (Lock):當某個指令要操作一筆資料時,先把它鎖起來,其他想操作這筆資料的指令必須在外面等待,直到前面的指令執行完畢並釋放鎖。
在程式中,我們可能會這樣寫:
wLock.lock();
try {
// do some instructions
} finally {
wLock.unlock();
}
這段程式碼確保了:
try {...} 區塊可以包含多個指令看到上面的程式碼,有沒有覺得很眼熟?它跟資料庫的 Transaction 非常相似:
tx.start();
try {
// some sql instructions
} finally {
tx.commit();
}
Transaction 使用了類似 Lock 的機制來實現隔離性,它可以包含 1 到 n 個 SQL 指令,確保這些指令執行時能夠正確地處理並發問題。
💡 小提示:Transaction 提供不同的隔離級別 (Isolation Level),如 Read Committed、Repeatable Read、Serializable 等,讓你可以在效能與一致性之間做權衡。
SQL 指令主要就是 CRUD 操作,簡化來看就是讀 (Read) 和寫 (Write):
SELECT,A 表示操作的資料INSERT、UPDATE、DELETE,A 表示操作的資料💡 小提示:Tx 是 Transaction 的縮寫
來個小測驗:當我們操作資料庫時,大部分都是單句 CRUD(約佔 80%),那麼在資料庫中,何時會使用到 Transaction?
即使只有一句 SQL,關聯式資料庫也會用 Transaction 包裝。因為資料庫系統預設會把 autocommit 設為 true,所以每個 SQL 指令丟進來後,系統會自動加上 tx.start() 和 tx.commit()。
因此,Transaction 才是資料庫真正的操作單位,每一次的 SQL 執行都是一次 Transaction。
💡 小提示:你也可以關閉
autocommit,手動控制 Transaction 的開始和結束,這在需要多個 SQL 操作保持原子性時特別有用。
讓我們回顧一下 Transaction 的核心概念:
Transaction 實現了事務隔離 (Isolation):當有多個 Transaction 並發執行時,透過適當的隔離級別,可以避免資料不一致的問題(如髒讀、不可重複讀、幻讀等)。
有了這個機制,資料庫系統可以在保證正確性的前提下提升 throughput,讓一般開發者(甚至是麻瓜 🧙)也能輕鬆實現高效能的 CRUD 操作,而不需要自己處理複雜的並發控制。
雖然 Transaction 翻譯成「交易」,但它跟現實生活中的買賣交易完全無關,不要被名稱誤導了!

